Two of my Claude Code teammates spent part of last Tuesday arguing about a lockfile.
The dependencies teammate said a missing package-lock.json was a high-severity finding. A reproducibility issue. Builds drift, environments diverge, and debugging gets harder. Annoying, but not automatically catastrophic.
The security teammate disagreed. Without deterministic resolution, dependency installation can change underneath you. That is not just a reproducibility inconvenience. It is the same class of supply-chain risk that made the event-stream incident so painful: a trusted dependency path changed, a malicious package entered the tree, and developers had to reason backward from a compromised build.
Neither teammate was wrong. They were looking at the same finding through different domain lenses. The right answer was to let both ratings stand and add a cross-reference layer on top. I did not tell them to reach that resolution. They worked it out by messaging each other while I watched.
That moment is the thing agent teams exist to enable. It is also the rarest thing that happened during the build.
Most of what the team did could have been handled by plain subagents at a fraction of the cost. Knowing the difference is what this post is about.
What agent teams actually are
A quick refresher, since the terminology gets muddled fast.
Subagents in Claude Code are workers that the main session spawns, delegates work to, and collects results from. They do not talk to each other. They report up.
Agent teams are different. Each teammate is a separate Claude Code session with its own context window. They share a task list. They send each other messages. They can disagree, negotiate, and resolve things without the lead brokering every exchange.
Both patterns parallelize work. Only one lets the workers coordinate as peers.
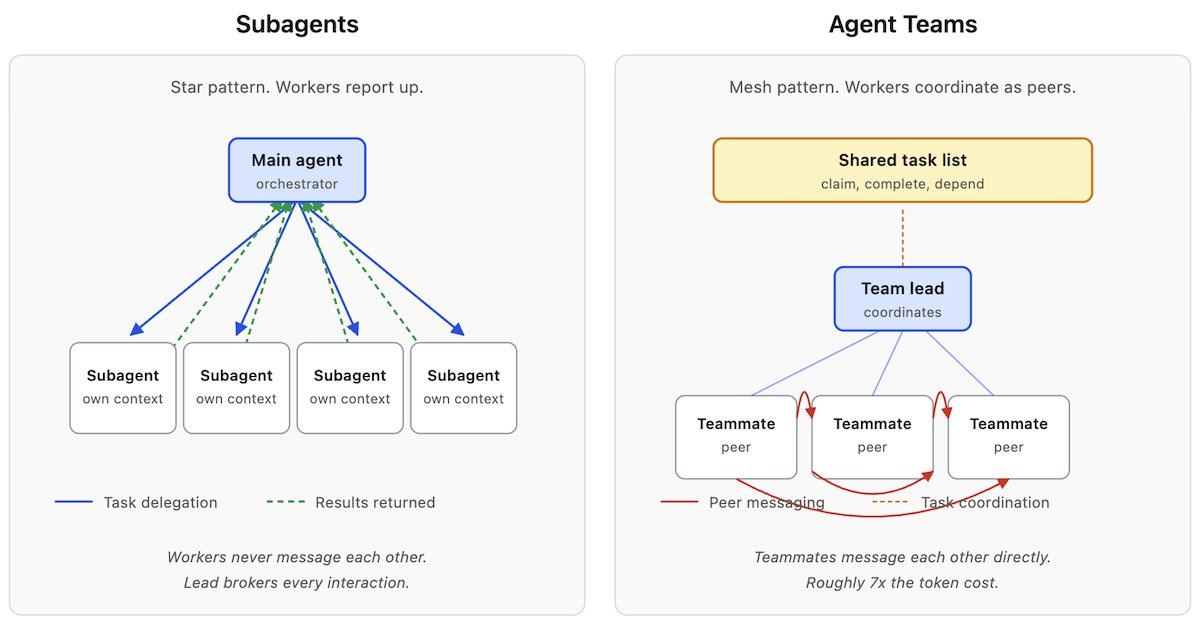
Subagents report up to the lead. Agent teams coordinate as peers through a shared task list.
Anthropic's docs are clear that agent teams use significantly more tokens than a single session. Each teammate has its own context window, and token usage scales with the number of active teammates. The docs also call out coordination overhead and diminishing returns as team size grows.
One third-party estimate from Verdent puts a 3-agent team at roughly 7x the token usage of a standard single-agent session. I would not treat that as an Anthropic benchmark, but it is a useful field estimate. Your mileage will vary with model choice, team size, repo size, and workflow length.
Agent teams are experimental and disabled by default. To enable them, set CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS to 1 in your settings.json or shell environment. You also need Claude Code v2.1.32 or later.
That cost profile is the entire question. Agent teams are not faster subagents. They are a more expensive coordination pattern. The work has to need that coordination.
The demo: a repo health auditor
I wanted to test agent teams on something real, not a research exercise. So I asked the team to build a CLI tool called repo-health. It audits a Git repository across four domains: dependencies, security, test coverage, and CI configuration. The output is a Markdown report with structured findings.
Four domains, four teammates, one shared codebase. The kind of work that looks parallelizable on the surface but has overlapping concerns underneath. A missing lockfile is a dependencies finding and a security finding. An untested error path is a test coverage finding and a CI finding when CI does not run tests. The interesting question was whether the team would notice those overlaps and do something useful with them.
Here is the full prompt I used.
Create an agent team to build a small but production-quality CLI tool called
"repo-health" that audits a Git repository and produces a structured report.
The tool should:
- Accept a path to a local Git repo as an argument
- Output a Markdown report with findings across four domains
- Be written in TypeScript with Node.js, using a single dependency footprint
(commander for CLI parsing, nothing else heavy)
- Include a README, a working test suite, and a sample report run against
this repo itself
Spawn four specialist teammates. Each one owns a domain and a corresponding
module in the codebase:
1. Dependencies teammate: parses package.json and lockfiles, reports local
dependency hygiene signals, flags missing deterministic install inputs,
and notes license risk where local metadata supports it.
2. Security teammate: scans for common smells (hardcoded secrets, unsafe
regex, dangerous shell calls, missing input validation on CLI args).
3. Test coverage teammate: inspects the test setup, identifies untested
modules and error paths, and reports coverage gaps.
4. CI configuration teammate: reads .github/workflows or equivalent, checks
whether tests appear to run, notes whether local repo data can verify
security scans, and calls out that merge-blocking behavior requires
branch protection or repository ruleset data outside the local repo.
Coordination requirements, not just parallel work:
- Before any teammate writes code, all four must agree on the shared report
schema (the TypeScript interface for a Finding) so their outputs compose
cleanly. Have them negotiate this in the shared task list.
- When the security teammate finds an issue tied to a dependency, it must
message the dependencies teammate so the recommendation accounts for it.
- When the test coverage teammate finds a gap, it must message the CI
teammate to verify whether CI would have caught the gap.
- Have them surface at least two genuine disagreements during the build
(for example, severity ratings, or whether a finding belongs to one domain
or another) and resolve them through direct messaging, not by escalating
to the lead.
Lead responsibilities:
- Require plan approval before any teammate writes code. Only approve plans
that include test coverage for the module.
- Synthesize the final report structure and write the top-level CLI entry
point that composes the four specialist modules.
- After the tool is built, run it against this repo and include the output
in the README as a worked example.
Quality gates:
- Every module must have at least one passing test.
- No teammate may edit another teammate's module without sending a message
explaining why.
- The final report must include a "limitations" section written by the lead.
When the build is complete, produce a postmortem document covering: which
teammate-to-teammate messages actually changed an outcome, where coordination
overhead exceeded its value, and what would have worked better as plain
subagents.
The prompt does three deliberate things. It forces real peer coordination at the moment of the schema contract. It demands at least two genuine disagreements, which prevents the team from drifting into polite parallel work. And it ends with a postmortem requirement, which gives me primary-source material for honest analysis instead of opinion.
One note on plan approval mode, which the prompt invokes. Each teammate submitted a plan before writing code. The lead approved all four on the first pass, since each plan included test coverage and stayed within scope. No rejections, no rework.
That outcome is worth flagging. Plan approval is most valuable when the lead has clear criteria to enforce and a real chance of catching a plan that misses the mark. For a well-specified prompt like this one, plan approval added latency without catching anything. For a riskier task, it would be the most important guardrail in the workflow.
What the team built
The output landed in about two and a half minutes of wall-clock time. That measure covers the parallel implementation phase only, not the planning, schema definition, or postmortem write-up. The full session from prompt to final report ran closer to fifteen minutes. The final shape:
| Role | Module | Tests | Findings Produced |
|---|---|---|---|
| Lead | index.ts, report.ts, enrichment.ts | 4 | Composition |
| Dependencies | analyzers/dependencies.ts | 6 | 7 finding types |
| Security | analyzers/security.ts | 6 | 5 finding types |
| Test Coverage | analyzers/test-coverage.ts | 4 | 5 finding types |
| CI Configuration | analyzers/ci.ts | 2 | 5 finding types |
Eight source files. Five test files. Twenty-two tests, all passing. One runtime dependency. Twenty-two finding types across four domains.
That part of the story is unremarkable. Plain subagents would have produced something similar.
The interesting part is what happened between the teammates.
One important constraint: repo-health only reads the local repository. It does not call npm registry data, OSV, the GitHub Advisory Database, or private package registries. That means the dependency analyzer can report dependency hygiene signals from local files, but it cannot authoritatively identify outdated packages or known vulnerable versions. That distinction matters. A tool that reads files can flag risk. A tool that claims vulnerability intelligence needs a vulnerability data source.
The message threads that mattered
Four coordination threads stood out. Three changed the output. One was ceremony.
Thread one: the lockfile argument
This is the one I opened with. The security teammate pushed for critical severity on the missing lockfile finding. The dependencies teammate held the line at high. They resolved it without me by deciding that severity is domain-relative. Each module keeps its own rating, and the enrichment layer cross-references the security context when both domains flag related issues.
The result is visible in the final report. A user looking at DEP-002 sees "high severity, reproducibility risk" with an annotation that the security analyzer also considers this a supply-chain exposure. Neither domain had to overstep its scope. The reader gets the full picture.
This exchange would not have happened as a peer-to-peer debate with subagents. A single agent doing all four analyses would have picked one severity rating and moved on. Possibly the wrong one for whichever domain was last on its mind.
Thread two: the CI gap escalation
The test coverage teammate found three source files with no corresponding tests. Before reporting the finding, it messaged the CI teammate:
"I found 3 source files with no corresponding test. Does CI run tests at all?"
The CI teammate's response was more useful than a simple yes or no:
"No local CI configuration detected. These gaps are invisible to automation from the repository data I can inspect. Merge-blocking behavior would require branch protection or repository ruleset data outside this repo."
That exchange triggered the enrichment logic. Every test coverage finding now appends a warning: "Warning: no local CI workflow was found, so this gap would not be caught automatically by repository automation." The report also avoids claiming whether failed checks block merges, because GitHub requires status checks through branch protection or rulesets. A local file scan cannot prove that.
A single agent could have produced this connection, but it would have required holding both domains in working memory at the same time. The team structure made the cross-reference cheap and explicit.
Thread three: the eval-in-tests disagreement
The security teammate's initial implementation flagged every use of eval() in the codebase. That included test helpers, where dynamic execution can be legitimate when the test is exercising dynamic code paths. The test coverage teammate pushed back:
"eval() in test helpers can be legitimate for testing dynamic code paths. Treating it the same as production eval usage creates noise that drowns out real findings."
They resolved it by treating test-file matches differently. The analyzer now distinguishes production code from test code and downgrades test-only dynamic execution to a lower-risk annotation rather than treating it like a production finding.
That nuance matters. Test code still executes in CI and can have access to secrets, so test-only dynamic execution should not disappear entirely. But it should not drown out production findings either. This is exactly the kind of judgment call where domain challenge improves the result.
There is a second detail worth flagging. The security analyzer still risks false positives when regex patterns contain the literal string eval( as detection logic. The team noted this as a known limitation of regex-based detection rather than pretending the analyzer was smarter than it was. That kind of self-aware limitation is exactly what I want from analysis tooling.
The lead carried that self-awareness into the final report. Its limitations section calls out three things. Regex-based security detection has known false positives. Dependency checks are limited to local repository data unless the tool connects to registry or advisory sources. The test coverage analyzer infers gaps from file naming rather than running coverage instrumentation.
None of those are surprises. All of them are the kind of caveats I would want a junior engineer to surface in a code review. The fact that the lead synthesized them from teammate findings, rather than me prompting for each one, is a small win.
Thread four: schema negotiation
The prompt required all four teammates to agree on the shared report schema before writing code. In practice, the lead defined the Finding interface, the four teammates read it, and nobody proposed a change. The negotiation was zero rounds long.
interface Finding {
id: string; // e.g. "DEP-002"
domain: Domain; // "dependencies" | "security" | "test-coverage" | "ci"
severity: Severity; // "low" | "medium" | "high" | "critical"
title: string;
description: string;
remediation: string;
file?: string;
line?: number;
}
Eight fields. Universal across all four domains. Nothing to negotiate. The schema was simple enough that top-down definition was strictly faster than ceremony.
This is the most contrarian finding in the build, and the one I want engineering leaders to read carefully. A lot of multi-agent advice recommends upfront contract negotiation between agents. My data suggests that advice is conditional, not universal. Negotiation has a fixed cost. The schema's complexity has to clear that bar before the cost pays off.
When would negotiation actually matter? If the security teammate had wanted a cweId field, or dependencies had wanted a packageManager field, the negotiation would have surfaced those tensions early. For a flat universal schema, the lead just writes the interface.
The honest comparison: agent team versus subagents
Here is where the build's data lines up against the alternatives. I went back through every coordination point and asked whether plain subagents would have produced the same outcome.
| Aspect | Agent Team | Plain Subagents | Better As |
|---|---|---|---|
| Schema agreement | Four agents acknowledge a schema | Lead defines, subagents consume | Plain subagent |
| Parallel module implementation | Four named teammates | Four anonymous subagents | Plain subagent |
| Cross-module enrichment | Agents message each other | Lead or reviewer post-processes results | Either works |
| Disagreement resolution | Agents debate via messages | Lead decides or reviewer adjudicates | Agent team |
| Quality review | Teammates challenge each other | Dedicated reviewer subagent | Plain subagent |
Three of five categories were better served by plain subagents. One was a wash. One genuinely benefited from the agent team structure.
If you are wondering whether that ratio justifies the token multiplier reported for agent teams, you are asking the right question. For this particular task, it probably did not. The messages that changed outcomes were valuable. I could have approximated the same result with a dedicated reviewer subagent running after the four analyzers completed. Cheaper, simpler, and the reviewer would have had the full codebase context to work from.
The agent team earned its premium on exactly one dimension: surfacing genuine domain conflict. That is rare in most tasks. It is real in some.
When agent teams are worth it
Four coordination threads are a small sample, but the pattern matches what Anthropic's docs describe. Agent teams pay off when the work has all three of these properties:
-
Multiple domains with legitimate authority. The security teammate and the dependencies teammate disagreed because both were right within their own scope. If one domain trumps the others by default, you do not need a team. You need that one domain plus subagents.
-
Decisions that benefit from challenge. Severity ratings, boundary calls, naming choices, architectural splits. Things where a single agent's first answer is plausible but not necessarily the best. A team forces the second opinion to be earned, not assumed.
-
Work that is independent enough to parallelize but interlocked enough to need coordination. If the modules are truly independent, you want subagents. If they are deeply coupled, you want one session. Agent teams sit in the narrow middle.
The repo-health build hit two of those three. The four domains had legitimate authority. The severity decisions benefited from challenge. But the modules were genuinely independent, which made most of the team overhead unnecessary.
A better fit for agent teams: cross-layer debugging where frontend, backend, and database changes interact in non-obvious ways. PR reviews where security, performance, and test coverage need to be argued against each other rather than reported side by side. Hypothesis-driven incident investigation where five competing theories need to challenge each other until one survives.
A worse fit: anything where the work decomposes cleanly into independent slices. Most refactors. Most feature implementations. Most analysis tasks where the domains do not actually overlap.
What I would do differently
If I built repo-health again, I would not use an agent team. I would use four subagents with distinct prompts. A dedicated reviewer subagent would run after they complete and produce the enrichment annotations from a single context.
That setup would have caught the lockfile argument as a reviewer note rather than a teammate debate, which is fine. It would have caught the eval-in-tests issue as a refinement pass rather than an inter-agent message, which is also fine. The outcomes that mattered would have been preserved at a fraction of the token cost.
What I would keep from this experiment is the prompt structure for tasks that actually need teams. The "surface at least two genuine disagreements" instruction is the one I would carry forward. Without it, teams default to polite parallel work and you pay the team premium for subagent value.
The other keeper is the postmortem requirement. Any time I run an agent team in the future, the team will produce a postmortem analyzing its own coordination patterns. That document is the difference between speculation and evidence about when this pattern is worth it.
The takeaway
Agent teams in Claude Code are a real capability. They do something subagents cannot do, and they cost significantly more to do it. The question is whether your work produces enough of that something to justify the price.
For repo-health, the answer was probably no. For cross-layer debugging or adversarial code review, the answer is probably yes. For most of the daily engineering work that fills a sprint, the answer is almost certainly no, and the right tool is still subagents.
The bottleneck was never the stack. In this case, it was not the model either. It was whether the work required the model to argue with itself. Most work does not.
