Open Weights, Real Stakes: Running Gemma 4 31B Locally
Open Weights, Real Stakes: Running Gemma 4 31B Locally
Google dropped Gemma 4 yesterday. I had it running locally by last night. Here's what it actually looks like to pull a frontier-class open model onto your own hardware and why the local versus cloud question is getting more interesting, not simpler.
If you're an engineer or architect trying to decide whether open-weight models belong in production or just in a lab, this is the practical view: what the license changes, what the hardware actually demands, where the model is good enough, and where cloud still wins.
TL;DR
- Gemma 4 is the first Google open-weight release that feels materially different for enterprise and production conversations because Apache 2.0 removes the licensing ambiguity that held earlier Gemma releases back.
- The 31B dense model is legitimately capable on local hardware, but the hardware reality still matters: quantization choice, memory headroom, and latency tradeoffs determine whether this is usable or merely impressive.
- Cloud models still hold the frontier on raw reasoning quality and freshness, especially for tasks that depend on recent APIs, libraries, or events.
- The most interesting architecture is not local or cloud. It's hybrid inference, where the orchestration layer routes each task based on sensitivity, complexity, and cost.
What "Open Weights" Actually Means (and Why Apache 2.0 Is the Real News)
Proprietary models like Claude, GPT-4o, and Gemini Pro work like a service. You send a prompt, their servers do the work, you get a response. You never see the model. You pay per token. The provider sets the terms.
Open weights flips that. The actual trained model parameters get published for anyone to download, run, and modify. Think of it as getting the recipe, not just the jar.
It's worth being precise here: "open weights" is not the same as "open source." Open source would include training data, full reproducibility, and the complete training stack. Open weights is narrower: you get the trained model file. That's still an enormous amount of power.
What makes Gemma 4 specifically notable is the license. Google shipped it under Apache 2.0, the most permissive commercial license in standard use. Previous Gemma models used Google's own Gemma license, which reserved the right to terminate access and restricted certain commercial deployments. Apache 2.0 removes both of those constraints entirely. You can modify it, fine-tune it, deploy it on-premises, embed it in a product, and Google cannot pull that access back.
For enterprise use cases with data residency requirements, legal holds, or vendor dependency concerns, that distinction is not academic. It changes whether this is just interesting technology or something you can realistically build around.
The Four Models: Know What You're Actually Running
Before pulling anything, know what you're getting into. Gemma 4 ships in four sizes:
- E2B / E4B ("Effective" models): Built for smartphones and edge devices. The E2B runs in under 1.5GB of memory and supports native audio input. These are also the foundation for Gemini Nano 4 on Android.
- 26B MoE (Mixture of Experts): 26 billion total parameters, but only 3.8 billion activate during any given inference pass. This makes it significantly faster and lighter on VRAM than a dense model of comparable size. The tradeoff is reasoning depth on long, chained tasks. MoE architectures excel at breadth, routing, retrieval, and classification-style work. They're less suited to sustained multi-step reasoning chains that require holding a lot of state. For most local use cases, this is actually the more practical option.
- 31B Dense: Maximum raw quality. Ranks third on the Arena AI open model leaderboard among open models. This is what I've been running for all of the tests below.
Hardware reality check before you pull the 31B: The Q8_0 quantized version requires approximately 35GB of VRAM to run. Q8_0 is worth choosing when you have the headroom. It is nearly indistinguishable from full bfloat16 precision, preserving essentially all the model's capability while reducing the file size. If your setup can't support 35GB, the 26B MoE at Q4_K_M is a better fit and still impressive. Both models ship with a 256K token context window.
Local vs. Cloud: The Actual Tradeoffs
I run both frontier cloud models and local models for personal AI agents, mostly to learn and push local inference to its limits. These are genuinely different tools with different strengths.
Where cloud models are still the right answer
The best cloud models operate above what any locally runnable model can currently match on raw reasoning quality at the frontier. Anthropic isn't shipping Claude 3.7 to your laptop. Google isn't giving you Gemini Ultra to run in your garage. The capability gap at the absolute top is real.
Cloud also wins on operational simplicity: no hardware to manage, no inference server to operate, continuous model updates, and clean API integration. For most teams building production AI features without data constraints, the cloud is still the right default.
Where local changes the math
Regulated and sensitive data. This is the most underappreciated argument for local inference. If your application touches PHI, PII, MNPI, attorney-client communications, or any data under a legal hold, every cloud API call is a compliance conversation. A local model eliminates that problem by design. No prompt ever leaves your network.
Latency at the edge. Agentic workflows chain many model calls together. Cloud round-trip latency compounds across a long chain. Local inference removes the network hop entirely. For embedded, on-device, or real-time applications, this is often the only viable path.
Cost at volume. Per-token API pricing is easy to underestimate at scale. Running your own inference converts a variable operational cost into a capital cost on hardware. Rough math: a workstation-class GPU setup capable of running Gemma 4 31B costs somewhere in the $3,000 to $8,000 range depending on configuration. At moderate inference volume, the API equivalent can exceed that in months.
Fine-tuning and customization. Apache 2.0 means you can take these weights and train on your own domain-specific data. That capability is enormously valuable for enterprise use cases where the general model needs to learn your terminology, your workflows, or your internal knowledge. You own the resulting model outright.
Learning the actual system. Running your own model forces you to engage with how these systems actually work: quantization levels, context window management, inference parameters, and prompt engineering that accounts for local model behavior. The feedback loop for understanding is dramatically tighter than routing everything through an API.
Running Gemma 4 31B (Q8_0): What I Actually Found
I ran this on a Mac Mini M4 Pro with 48GB of unified memory using Ollama. Here's what I tested and where I landed.
Vision: Seeing What's Actually There
Gemma 4's multimodal capabilities are native across all model sizes, not bolted on. I fed it real images to find out how well they actually work in practice.
First test: a photo of a classic red Ferrari alongside a person. The model identified the specific model family, the "cheese grater" side strakes as a signature design element of that era, the paint color by its proper name, and described the person's attire in detail. No prompting tricks. Just the image and a simple question.
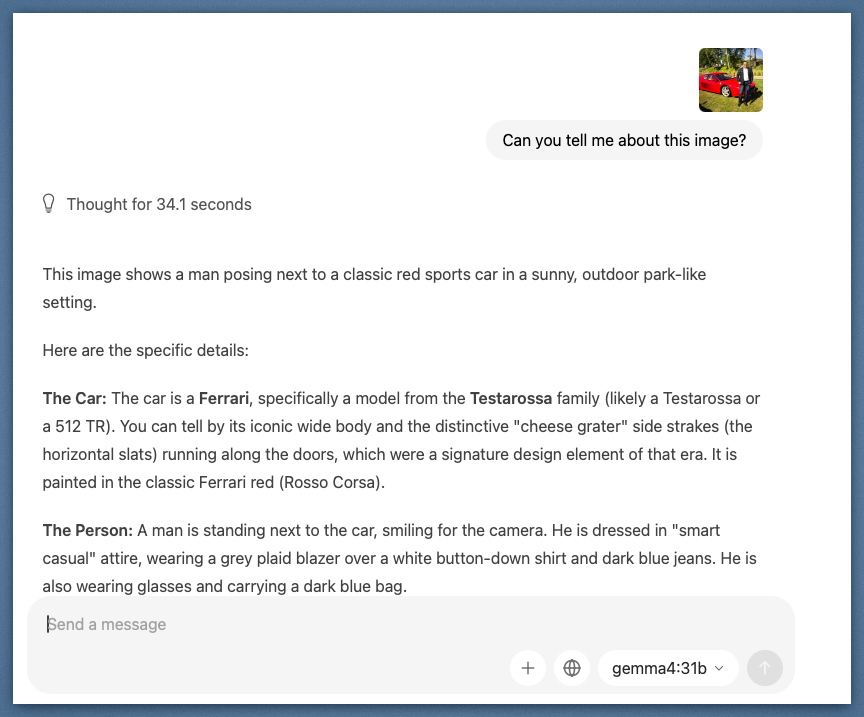 The model identified the Testarossa body style, era, and design details from a single photo. Thought for 34.1 seconds before responding.
The model identified the Testarossa body style, era, and design details from a single photo. Thought for 34.1 seconds before responding.
Second test: a professional headshot. I used a real photo from a recent headshot session to keep the test grounded. The model analyzed subject expression, clothing details including the specific tie pattern, lighting, and composition quality, all accurately.
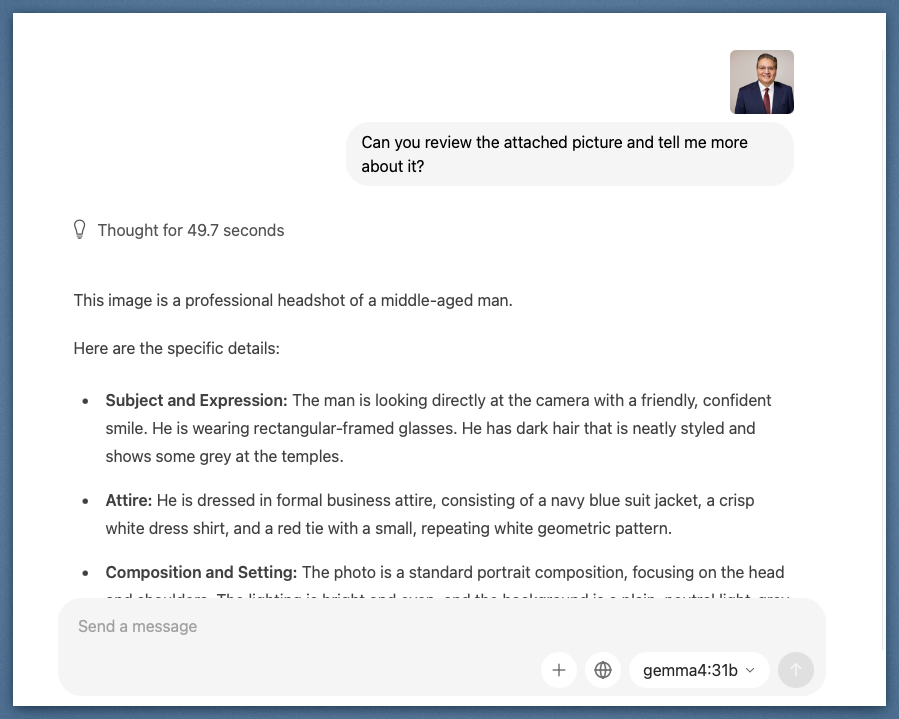 Accurate detail extraction from a standard portrait: attire, expression, composition, and lighting conditions.
Accurate detail extraction from a standard portrait: attire, expression, composition, and lighting conditions.
What's interesting here is the thinking time. Both vision prompts showed 30 to 50 seconds of deliberation before output. You can expand that thinking chain and see it reasoning through observations before synthesizing them.
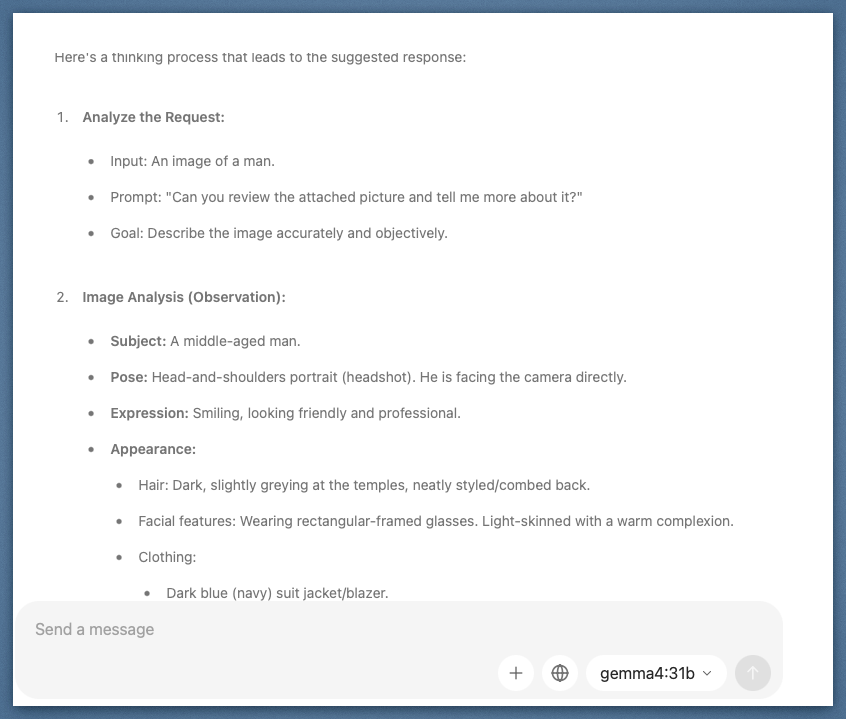 The expanded thinking block shows the model cataloging observations before drafting its response. Image analysis broken into discrete reasoning steps.
The expanded thinking block shows the model cataloging observations before drafting its response. Image analysis broken into discrete reasoning steps.
Reasoning Chain: Where It Gets Interesting
This is the capability I care about most for engineering work. Configurable extended thinking mode lets the model reason step by step before committing to an answer. More importantly, it exposes the kind of intermediate correction and reframing that matters when you're evaluating whether a model can be trusted inside a workflow.
I gave it a realistic cloud migration scenario: 400 workloads, 18-month timeline, 200 engineers with only 30 having significant cloud experience, a hard PCI-DSS compliance deadline at month 12, and a 30% cost reduction target by month 18.
The thinking block tells the real story. The model identified four separate challenges, began structuring a sequencing strategy, and then stopped mid-reasoning to question its own approach. The exact moment: "Wait, let's refine the Sequencing Strategy." It revised the wave structure before producing the final answer.
 The model caught its own sequencing flaw mid-thought and corrected it before responding. That's the reasoning chain doing its job.
The model caught its own sequencing flaw mid-thought and corrected it before responding. That's the reasoning chain doing its job.
The final output landed on a "Hybrid Phased Wave Strategy" with four distinct migration waves, sequenced to address the skill gap constraint first, compliance deadline second, and cost optimization third. It named the traps (lift and shift fails the cost goal; full refactor fails the timeline and skill gap), then built around them.
 78 seconds of local inference, no network call, no token bill. The output structured a four-wave migration plan around the actual constraints in the prompt.
78 seconds of local inference, no network call, no token bill. The output structured a four-wave migration plan around the actual constraints in the prompt.
Instruction following is sharper than I expected. Instruction adherence has historically been the weakest point of local models below the frontier. Gemma 4 31B holds complex instructions well across long contexts and follows structured output formats consistently. Native function calling support is a genuine upgrade over earlier Gemma generations that required prompt engineering workarounds.
Code generation is competitive on mid-complexity tasks. I ran real engineering problems at it: refactoring patterns, code explanation, generating boilerplate with specific constraints. For problems that don't require deep contextual reasoning across a large codebase, the output quality was solid enough to use as a first pass.
The knowledge cutoff is a real operational constraint. Training data ends at January 2025. That is 15 months of missing context as of this writing. For anything involving recent frameworks, recent events, or current API versions, you will hit that wall. This isn't a footnote limitation. It's a meaningful filter on which use cases actually make sense.
The 256K context window holds up. I fed a large document corpus into a single prompt. It processed cleanly without degradation. Context length has historically been Achilles' heel of local models. That gap is closing.
Where it still struggles: Multi-step reasoning chains requiring sustained state, nuanced creative tasks, and anything requiring knowledge from the last year and a half. For those, I still route to Claude via the cloud.
Gemma 4 also ships with configurable thinking modes across all model sizes. You can dial reasoning depth up or down depending on task complexity, which is a practical tool for managing latency on a local setup.
The Architecture Worth Building: Hybrid Inference
Here is the pattern I keep coming back to, and the one I think is most interesting for engineering teams right now.
Not every task in an agentic workflow needs the same model. A pipeline that summarizes internal documents, routes them to the right team, and drafts a response has at least three distinct inference steps with very different requirements. The summarization step might involve sensitive data that cannot leave your network. The routing step is simple classification. The drafting step might benefit from the best reasoning model available.
A hybrid inference architecture picks the right tool for each step: local model for the data-sensitive or high-volume steps, cloud model for the steps that need maximum capability and have no data constraints. The orchestration layer, not the model itself, decides where each call goes.
This is roughly what that routing seam looks like in practice:
// Task metadata is the contract between agents and the routing layer.
type Task = {
kind: 'summarize' | 'classify' | 'draft' | 'code';
sensitivity: 'public' | 'internal' | 'regulated';
complexity: 'low' | 'medium' | 'high';
tokens: number;
payload: unknown;
};
enum TargetModel {
LocalGemma4 = 'gemma4-31b-local',
CloudFrontier = 'cloud-frontier-model'
}
function route(task: Task): TargetModel {
const isSensitive =
task.sensitivity === 'regulated' || task.sensitivity === 'internal';
const isHighVolume = task.tokens > 64_000;
if (isSensitive || isHighVolume) {
return TargetModel.LocalGemma4;
}
const needsFrontierReasoning =
task.kind === 'draft' && task.complexity === 'high';
if (needsFrontierReasoning) {
return TargetModel.CloudFrontier;
}
return TargetModel.LocalGemma4;
}
async function handleTask(task: Task) {
const target = route(task);
if (target === TargetModel.LocalGemma4) {
return callLocalGemma4(task);
}
return callCloudFrontier(task);
}
In practice, that's the right mental model. Agents should describe intent. The policy layer should decide where inference runs based on sensitivity, complexity, latency, and cost.
This isn't theoretical. It's the natural evolution of what teams are already building with retrieval-augmented generation and multi-model pipelines. Open weights models like Gemma 4 31B make the local leg of that architecture genuinely viable for the first time.
So: Learning Tool or Production Asset?
The gap argument keeps shifting shape.
A year ago, local models were clearly better for tinkering than for production. Today, Gemma 4 31B ranks third among open models on standard benchmarks, runs on hardware many engineers already own or can buy with a single capital request, and ships under a license that lets you deploy it anywhere without asking permission.
For privacy-constrained data, high-volume inference, edge devices, and domain-specific fine-tuning use cases, this is a production asset right now.
For tasks requiring frontier reasoning quality with no data constraints, cloud is still the right answer, and the ceiling there keeps rising.
The most interesting question is not which one wins. It's how you design the seam between them. That's where the real architecture work is now.
What are you building with open models? Have you pushed one into production, or is local inference still sitting in the experimentation column for you? I'm particularly curious whether anyone is running a hybrid architecture in a real environment and what the orchestration, observability, and policy layer look like.
Find me on LinkedIn or drop a comment. I want to know what's actually working.
Share this post
Related Posts
From Copy-Paste to Skill: What Thousands of AI Coding Sessions Taught Me About Guardrails
After thousands of sessions with Claude Code, Codex, Kiro, and every other LLM-based CLI and IDE, I distilled what I learned into a reusable Claude Skill. Here's how those lessons became the guardrails that let me move faster and actually trust the output.
The Rise of MCP Servers: Why Every Developer Will Have a Personal AI Toolchain
From AWS to GitHub to Podman, MCP servers are quietly becoming the new plug-in ecosystem for developers—and it’s changing how we work.
From Procrastination to Privacy-First Productivity (Part 2)
After building two open-source task managers to battle procrastination, I took it further — secure cloud sync, end-to-end encryption, and now an MCP server that connects your tasks to AI.